
Да, умеет. Можете описать вашу бизнес-задачу, и какие данные в файлах? Я тогда подробно напишу, как удобнее это сделать.

Имеется основная база клиентов, с паспортами, фио, и 1 еще одним уникальным параметром. Нужно как то довести до автоматизма чтобы я, загружая дополнительную базу клиентов по которым была проведена "какая-либо" работа, сравнивалась с основной базой и из основной базы исключались эти клиенты, а затем я мог скачать "очищеную" основную базу.
Дадата умеет делать примерно такую штуку.
Пусть у вас есть основная база в файле 1_Исходные.xlsx:
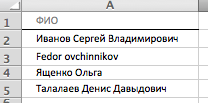
И дополнительная база в файле 2_Свежие.xlsx:
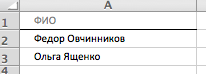
Вы прогоняете файлы через поиск дублей и получаете результат:
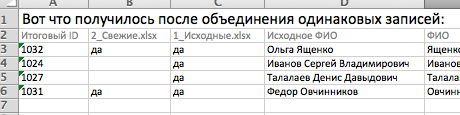
Дальше фильтруете по условию «1_Исходные.xlsx = да» и «2_Свежие.xlsx = пусто» и получаете только тех клиентов, которые есть в основной базе, и при этом отсутствуют в дополнительной базе. То есть то, что вас и интересует.
Но, к сожалению, сейчас Дадата не умеет искать дубли с учетом паспортов. Планируем добавить это в 2017 году.
Если будут поддерживаться паспорта, вам подойдет сценарий, как я его описал выше?
Сервис поддержки клиентов работает на платформе UserEcho
Дадата умеет делать примерно такую штуку.
Пусть у вас есть основная база в файле 1_Исходные.xlsx:
И дополнительная база в файле 2_Свежие.xlsx:
Вы прогоняете файлы через поиск дублей и получаете результат:
Дальше фильтруете по условию «1_Исходные.xlsx = да» и «2_Свежие.xlsx = пусто» и получаете только тех клиентов, которые есть в основной базе, и при этом отсутствуют в дополнительной базе. То есть то, что вас и интересует.
Но, к сожалению, сейчас Дадата не умеет искать дубли с учетом паспортов. Планируем добавить это в 2017 году.
Если будут поддерживаться паспорта, вам подойдет сценарий, как я его описал выше?